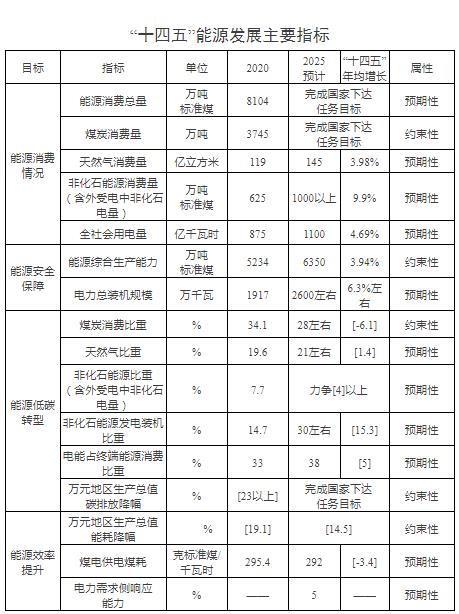
使用简单方法在图像中检测血细胞
对象检测问题的基础是数据的外观。现在,本文将介绍可用于解决对象检测问题的不同深度学习架构。让我们首先讨论我们将要处理的问题陈述。
目录
1. 了解问题陈述:血细胞检测
2. 数据集链接
3. 解决对象检测问题的简单方法
4. 实施简单方法的步骤
· 加载数据集
· 数据探索
· 为简单方法准备数据集
· 创建训练和验证集
· 定义分类模型架构
· 训练模型
· 作出预测
5. 结论
了解问题陈述血细胞检测
问题陈述
对于一组给定的血细胞图像,我们必须检测图像中的白细胞。现在,这是来自数据集的示例图像。如你所见,你可以看到有一些红色阴影区域和蓝色或紫色区域。

在上图中,红色阴影区域是红细胞(RBC),紫色阴影区域是白细胞(WBC),还有一些小的黑色突出部分是血小板。
正如你在此图像中看到的那样,我们有多个对象和多个类。
为简单起见,我们将其转换为单类单对象问题。这意味着我们将只考虑白细胞。
因此,只有一个类,即白细胞,而忽略其余的类。此外,我们将只保留具有单个白细胞的图像。
因此,具有多个白细胞的图像将从该数据集中删除。
以下是我们将从该数据集中选择图像的方法。

因此,我们删除了图像 2 和图像 5,因为图像 5 没有白细胞,而图像 2 有 2 个白细胞,其他图像保留在数据集中。同样,测试集也将只有一个白细胞。
现在,对于每个图像,我们在白细胞周围都有一个边界框。正如你在这张图片中看到的,我们的文件名为 1.jpg,这些是白细胞周围边界框的边界框坐标。

在下一节中,我们将介绍解决此对象检测问题的简单方法。
解决对象检测问题的简单方法
在本节中,我们将讨论一种解决对象检测问题的简单方法。所以让我们首先了解任务,我们必须在血细胞图像中检测白细胞,可以看到下图。

现在,最简单的方法是将图像划分为多个块,因此对于此图像,将图像划分为四个块。

我们对这些块中的每一个进行分类,因此第一个块没有白细胞,第二个块有一个白细胞,同样第三个和第四个没有任何白细胞。

我们已经熟悉分类过程以及如何构建分类算法。因此,我们可以轻松地将这些单独的块中的每一个分类为 yes 和 no,以表示白细胞。
现在,在下图中,具有白细胞的块(绿色框)可以表示为边界框,因此在这种情况下,我们将取这个块的坐标值,并将其返回为白细胞的边界框。

现在为了实施这种方法,我们首先需要准备我们的训练数据。
现在可能有一个问题,为什么我们需要准备训练数据?我们已经有了这些图像和边界框。
我们的训练数据采用以下格式,其中我们有白细胞边界框和边界框坐标。

现在,请注意我们有完整图像的这些边界框坐标,但我们将把这个图像分成四个块。我们需要所有这四个块的边界框坐标。下一个问题是我们如何做到这一点?
我们必须定义一个新的训练数据,我们有文件名,如下图所示。
我们有不同的块,对于每个块,我们有 Xmin、Xmax、Ymin 和 Ymax 值,它们表示这些块的坐标,最后,我们的目标变量是白细胞。图像中是否存在白细胞?

现在在这种情况下,它将成为一个简单的分类问题。因此,对于每个图像,我们将其划分为四个不同的块,并为每个块创建边界框坐标。
现在下一个问题是我们如何创建这些边界框坐标?这真的很简单。

考虑到我们有一个大小为 (640*480) 的图像。所以原点是(0,0)。上图有 x 轴和 y 轴,这里我们的坐标值为 (640, 480)。
现在,我们找出中点,它是 (320,240)。一旦我们有了这些值,我们就可以很容易地找出每个块的坐标。所以对于第一个块,我们的 Xmin 和 Ymin 将是 (0,0) ,而 Xmax, Ymax 将是 (320,240)。

同样,我们可以在第二个、第三个和第四个块中找到它。一旦我们有了这些块中的每一个的坐标值或边界框值。下一个任务是确定此块中是否存在白细胞。

在这里我们可以清楚地看到块 2 有白细胞,而其他块没有,但是我们不能在数据集中的每个块上对每个图像都手动标注白细胞。
现在在下一节中,我们将实现简单的方法。
实施简单方法的步骤
在上一节中,我们讨论了用于对象检测的简单方法。现在让我们定义在血细胞检测问题上实施这种方法的步骤。
这些是将要遵循的步骤:
1. 加载数据集
2. 数据探索
3. 为简单方法准备数据集
4. 创建训练和验证集
5. 定义分类模型架构
6. 训练模型
7. 作出预测
让我们进入下一节,实现上述步骤。
1.加载所需的库和数据集
因此,让我们首先从加载所需的库开始。numpy和pandas,matplotlib用来可视化数据,我们已经加载了一些库来处理图像并调整图像大小,最后是torch库。
# Importing Required Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import os
from PIL import Image
from skimage.transform import resize
import torch
from torch import nn
现在我们将修复一个随机种子值。
# Fixing a random seed values to stop potential randomnessseed = 42
rng = np.random.RandomState(seed)
在这里,我们将安装驱动器,因为数据集存储在驱动器上。
# mount the drive
from google.colab import drive
drive.mount('/content/drive')
现在因为驱动器上的数据以 zip 格式提供。我们必须解压缩这些数据,在这里我们将解压缩数据。
所以我们可以看到所有的图像都被加载并存储在一个名为 images 的文件夹中。在这个文件夹的末尾,我们有一个 CSV 文件,它是trained.csv。
# unzip the dataset from drive
!unzip /content/drive/My Drive/train_zedkk38.zip

2.数据探索
阅读 CSV 文件并找出存储在这个“train.csv”文件中的信息是什么。
## Reading target file
data = pd.read_csv('train.csv')
data.shape
打印 CSV 文件的前几行,我们可以看到该文件具有 image_names 以及 cell_type,它将表示红细胞或白细胞等等。最后是此特定图像中此特定对象的边界框坐标。data.head()

因此,如果我们检查红细胞、白细胞和血小板的计数值。我们将看到红细胞具有最大计数值,其次是白细胞和血小板。
data.cell_type.value_counts()

现在为简单起见,我们将只考虑白细胞。因此,我们选择了只有白细胞的数据。
现在我们针对这些图像有 image_names和 cell_type WBC。还有边界框坐标。
(data.loc[data['cell_type'] =='WBC']).head()

让我们看看原始数据集中的几张图像以及这些图像的形状。
我们可以看到这些图像的形状是(480,640,3)。这是一个具有三个通道的 RGB 图像,这是数据集中的第一张图像。
image = plt.imread('images/' + '1.jpg')
print(image.shape)
plt.imshow(image)

下一步是用这个图像创建块。我们要学习如何把这张图片分成四个块。现在我们知道图像的形状是 (640, 480)。因此这张图片的中间点是 (320,240),中心是 (0, 0)。

因此,我们有图像中所有这些块的坐标,在这里我们将利用这些坐标并创建块。
这些坐标的格式将是 Ymin、Ymax、Xmin 和 Xmax。这里我们的 (Ymin, Ymax) 是 (0, 240) 并且 (Xmin, Xmax) 是 (0,320)。这基本上表示第一个块。
同样,对于随后的第二个第三个和第四个块,我们有 image_2、image_3、image_4。这是一个我们可以从图像创建块的过程。
# creating 4 patches from the image
# format ymin, ymax, xmin, xmax
image_1 = image[0:240, 0:320, :]
image_2 = image[0:240, 320:640, :]
image_3 = image[240:480, 0:320, :]
image_4 = image[240:480, 320:640, :]

现在我们需要为这些块分配一个目标值。为了做到这一点,我们计算并集的交集,我们必须找出交集区域和并集区域。

所以交集区域就是这个特定的矩形,要找出面积,我们需要找出这个矩形的 Xmin、Xmax 和 Ymin、Ymax 坐标。
def iou(box1, box2):
Irect_xmin, Irect_ymin = max(box1[0],box2[0]), max(box1[2],box2[2])
Irect_xmax, Irect_ymax = min(box1[1],box2[1]), min(box1[3],box2[3])
if Irect_xmax < Irect_xmin or Irect_ymax < Irect_ymin:
target = inter_area = 0
else:
inter_area = np.abs((Irect_xmax - Irect_xmin) * (Irect_ymax - Irect_ymin))
box1_area = (box1[1]-box1[0])*(box1[3]-box1[2])
box2_area = (box2[1]-box2[0])*(box2[3]-box2[2])
union_area = box1_area+box2_area-inter_area
iou = inter_area/union_area
target = int(iou > 0.1)
return target
我们有来自训练 CSV 文件的原始边界框坐标。当我将这两个值用作我们定义的“ iou”函数的输入时,目标为 1。
你也可以尝试使用不同的块,也可以基于你将得到的目标值。
box1= [320, 640, 0, 240]
box2= [93, 296, 1, 173]
iou(box1, box2)
输出为 0。现在下一步是准备数据集。
3.为简单方法准备数据集
我们只考虑并探索了数据集中的单个图像。因此,让我们对数据集中的所有图像执行这些步骤。这里是我们拥有的完整数据。
data.head()

现在,我们正在转换这些细胞类型,红细胞为0,白细胞为 1,血小板为 2。
data['cell_type'] = data['cell_type'].replace({'RBC': 0, 'WBC': 1, 'Platelets': 2})
现在我们必须选择只有一个白细胞的图像。

因此,首先我们创建数据集的副本,然后仅保留白细胞并删除任何具有多个白细胞的图像。
## keep only Single WBCs
data_wbc = data.loc[data.cell_type == 1].copy()
data_wbc = data_wbc.drop_duplicates(subset=['image_names', 'cell_type'], keep=False)
现在我们已经选择了图像。我们将根据输入图像大小设置块坐标。
我们正在逐一读取图像并存储该特定图像的白细胞边界框坐标,使用我们在此处定义的块坐标从该图像中提取块。
然后我们使用自定义的 IoU 函数找出每个块的目标值。最后,在这里我们将块大小调整为标准大小 (224, 224, 3)。在这里,我们正在为每个块创建最终输入数据和目标数据。
# create empty lists
X = []
Y = []
# set patch co-ordinates
patch_1_coordinates = [0, 320, 0, 240]
patch_2_coordinates = [320, 640, 0, 240]
patch_3_coordinates = [0, 320, 240, 480]
patch_4_coordinates = [320, 640, 240, 480]
for idx, row in data_wbc.iterrows():
# read image
image = plt.imread('images/' + row.image_names)
bb_coordinates = [row.xmin, row.xmax, row.ymin, row.ymax]
# extract patches
patch_1 = image[patch_1_coordinates[2]:patch_1_coordinates[3], patch_1_coordinates[0]:patch_1_coordinates[1], :]
patch_2 = image[patch_2_coordinates[2]:patch_2_coordinates[3], patch_2_coordinates[0]:patch_2_coordinates[1], :]
patch_3 = image[patch_3_coordinates[2]:patch_3_coordinates[3], patch_3_coordinates[0]:patch_3_coordinates[1], :]
patch_4 = image[patch_4_coordinates[2]:patch_4_coordinates[3], patch_4_coordinates[0]:patch_4_coordinates[1], :]
# set default values
target_1 = target_2 = target_3 = target_4 = inter_area = 0
# figure out if the patch contains the object
## for patch_1
target_1 = iou(patch_1_coordinates, bb_coordinates )
## for patch_2
target_2 = iou(patch_2_coordinates, bb_coordinates)
## for patch_3
target_3 = iou(patch_3_coordinates, bb_coordinates)
## for patch_4
target_4 = iou(patch_4_coordinates, bb_coordinates)
# resize the patches
patch_1 = resize(patch_1, (224, 224, 3), preserve_range=True)
patch_2 = resize(patch_2, (224, 224, 3), preserve_range=True)
patch_3 = resize(patch_3, (224, 224, 3), preserve_range=True)
patch_4 = resize(patch_4, (224, 224, 3), preserve_range=True)
# create final input data
X.extend([patch_1, patch_2, patch_3, patch_4])
# create target data
Y.extend([target_1, target_2, target_3, target_4])
# convert these lists to single numpy array
X = np.array(X)
Y = np.array(Y)
现在,让我们打印原始数据和刚刚创建的新数据的形状。我们可以看到我们最初有 240 张图像。
现在我们将这些图像分成四部分, 即(960,224,224,3)。这是图像的形状。
# 4 patches for every image
data_wbc.shape, X.shape, Y.shape
让我们快速看一下我们刚刚创建的这些图像之一。这是我们的原始图像,这是原始图像的最后一个块或第四个块。我们可以看到分配的目标是1。
image = plt.imread('images/' + '1.jpg')】
plt.imshow(image)

如果我们检查任何其他块,假设我要检查此图像的第一个块,这里会将目标设为0。你将获得第一个块。
同样,你可以确保将所有图像转换为块并相应地分配目标。
plt.imshow(X[0].astype('uint8')), Y[0]

4.准备训练和验证集
现在我们有了数据集。我们将准备我们的训练和验证集。现在请注意,这里我们的图像形状为 (224,224,3)。
# 4 patches for every image
data_wbc.shape, X.shape, Y.shape
输出是:
((240, 6), (960, 224, 224, 3), (960,))
在 PyTorch 中,我们首先需要拥有通道。因此,我们将移动具有形状 (3,224,224) 的轴。
X = np.moveaxis(X, -1, 1)
X.shape
输出是:
(960, 3, 224, 224)
现在,我们对图像像素值进行归一化。
X = X / X.max()
使用训练测试拆分功能,我们将创建一个训练集和验证集。
from sklearn.model_selection import train_test_split
X_train, X_valid, Y_train, Y_valid=train_test_split(X, Y, test_size=0.1, random_state=seed)
X_train.shape, X_valid.shape, Y_train.shape, Y_valid.shape
上述代码的输出是:
((864, 3, 224, 224), (96, 3, 224, 224), (864,), (96,))
现在,我们要将训练集和验证集都转换为张量,因为它们是“ numpy”数组。
X_train = torch.FloatTensor(X_train)
Y_train = torch.FloatTensor(Y_train)
X_valid = torch.FloatTensor(X_valid)
Y_valid = torch.FloatTensor(Y_valid)
5.模型构建
现在,我们要构建我们的模型,在这里我们安装了一个库,它是 PyTorch 模型摘要。
!pip install pytorch-model-summary

这仅用于在 PyTorch 中打印模型摘要。现在我们从这里导入汇总函数。
from pytorch_model_summary import summary
这是我们为方法定义的架构。
我们定义了一个顺序模型,其中有Conv2d 层,输入通道数为 3,过滤器数量为 64,过滤器的大小为 5,步幅设置为 2。对于这个 Conv2d 层有 ReLU 激活函数。一个池化层,窗口大小为 4,步幅为 2,然后是卷积层。
现在展平 Conv2d 层的输出,最后是全连接层和 sigmoid 激活函数。
## model architecture
model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5, stride=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=4,stride=2),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=5, stride=2),
nn.Flatten(),
nn.Linear(40000, 1),
nn.Sigmoid()
)
在这里打印模型,将是我们定义的模型架构。
print(model)

使用summary函数,我们可以查看模型摘要。因此,这将为我们返回每个层的输出形状,每个层的可训练参数的数量。现在我们的模型已经准备好了。
print(summary(model, X_train[:1]))

现在模型已经准备好训练了。
6.训练模型
让我们训练这个模型。所以我们要定义我们的损失函数和优化函数。我们将二元交叉熵定义为损失和Adam优化器。然后我们将模型传输到 GPU。
在这里,我们从输入图像中提取批次来训练这个模型。
## loss and optimizer
criterion = torch.nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
## GPU device
if torch.cuda.is_available():
model = model.cuda()
criterion = criterion.cuda()
因此,我们从 x_train 中提取了批次并使用了这些批次。我们将对该模型进行总共 15 个 epoch 的训练。我们还设置了一个 optimizer.Zero_grad() 并将输出存储在这里。
现在我们正在计算损失并存储所有损失并执行反向传播和更新参数。此外,我们在每个 epoch 之后打印损失。
在输出中,我们可以看到每个时期的损失都在减少。所以这个模型的训练就完成了。
# batch size of the model
batch_size = 32
# defining the training phase
model.train()
for epoch in range(15):
# setting initial loss as 0
train_loss = 0.0
# to randomly pick the images without replacement in batches
permutation = torch.randperm(X_train.size()[0])
# to keep track of training loss
training_loss = []
# for loop for training on batches
for i in range(0,X_train.size()[0], batch_size):
# taking the indices from randomly generated values
indices = permutation[i:i+batch_size]
# getting the images and labels for a batch
batch_x, batch_y = X_train[indices], Y_train[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda().float(), batch_y.cuda().float()
# clearing all the accumulated gradients
optimizer.zero_grad()
# mini batch computation
outputs = model(batch_x)
# calculating the loss for a mini batch
loss = criterion(outputs.squeeze(),batch_y)
# storing the loss for every mini batch
training_loss.append(loss.item())
# calculating the gradients
loss.backward()
# updating the parameters
optimizer.step()
training_loss = np.average(training_loss)
print('epoch: t', epoch, 't training loss: t', training_loss)

7.做出预测
现在让我们使用这个模型来进行预测。所以在这里我只从验证集中获取前五个输入并将它们传输到 Cuda。
output = model(X_valid[:5].to('cuda')).cpu().detach().numpy()
这是我们拍摄的前五张图像的输出。现在我们可以看到前两个的输出是没有白细胞或有白细胞。
output
这是输出:
array([[0.00641595],
[0.01172841],
[0.99919134],
[0.01065345],
[0.00520921]], dtype=float32)
绘制图像。我们可以看到这是第三张图片,这里的模型说有一个白细胞,我们可以看到这张图片中有一个白细胞。
plt.imshow(np.transpose(X_valid[2]))

同样,我们可以检查另一张图像,因此将获取第一张图像。
你可以看到输出图像,这个图像是我们的输入块,这个块中没有白细胞。
plt.imshow(np.transpose(X_valid[1]))

这是一种非常简单的方法,可以进行预测或识别具有白细胞的图像的块或部分。
结论
使用简单方法了解使用图像数据集进行血细胞检测的实际实现。这是解决业务问题和开发模型的真正挑战。
在处理图像数据时,你必须分析一些任务,例如边界框、计算 IoU 值、评估指标。本文的下一个级别(未来任务)是一个图像可以有多个对象。任务是检测每个图像中的对象。希望这些文章能帮助你了解如何使用图像数据检测血细胞,如何建立检测模型,我们将使用这种技术,并将其应用于医学分析领域。
原文标题:使用简单方法在图像中检测血细胞
郑重声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。
相关阅读




猜你喜欢
-
CCD图像传感器和CMOS图像传感器的区别详解
2022-03-11 -
?使用Mediapipe对图像进行手部地标检测
2022-03-08 -
在OpenCV中使用图像像素
2022-03-03 -
使用OpenCV在Python中进行图像操作
2022-02-14 -
使用迁移学习加强你的图像搜索
2022-02-10 -
基于域相关的图像增强
2022-01-06 -
探索如何通过向AI提供大量药丸图像来训练AI检测定制药丸
2021-12-15 -
中国工程院院士杜祥琬:减污降碳不是简单地拉闸限电
2021-10-20 -
煤电纠缠囧境:“双控”叠加库存锐减,拉闸成了最简单的办法?
2021-09-26 -
一文教你使用EasyOCR从图像中检测文本:实践指南
2021-09-15 -
1亿像素!三星将推5.76亿像素图像传感器
2021-09-10 -
一文了解如何使用CNN进行图像分类
2021-09-02 -
2万公里保一次,只换空调滤,电动汽车保养真有这么简单吗?
2021-08-25 -
油价下跌的简单原因
2021-08-14 -
AI运算能力助阵,这届东京奥运会不简单!
2021-08-13