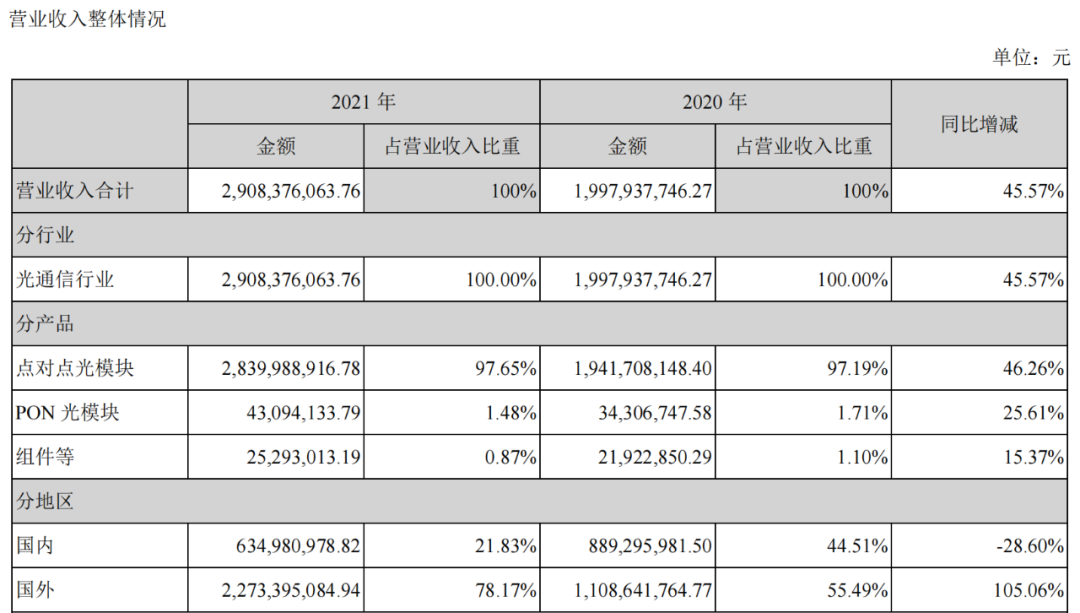
用Pytorch训练神经网络
本文目标是如何使用Pytorch以尽可能短的方式从图像中预测颜色、填充级别等连续属性。我们将学习加载现有网络,修改它以预测特定属性,并用不到40行代码(不包括空格)对其进行训练。
Standart神经网络通常专注于分类问题,比如识别猫和狗。然而,这些网络可以很容易地进行修改,从图像中预测连续属性,如年龄、大小或价格。
首先,让我们导入软件包并定义主要的训练参数:
import numpy as np
import torchvision.models.segmentation
import torch
import torchvision.transforms as tf
Learning_Rate=1e-5
width=height=900
batchSize=1
学习率:是训练过程中梯度下降的步长。
宽度和高度是用于训练的图像的尺寸。训练过程中的所有图像都将调整为该大小。
batchSize:是将用于每次训练迭代的图像数。
batchSize,width,height将与训练的内存需求成比例。根据硬件的不同,可能需要使用较小的批处理大小来避免内存不足问题。
请注意,由于我们只使用单一大小的图像进行训练,因此训练后的网络可能仅限于使用这种大小的图像。
接下来,让我们创建训练数据。我们想做一个简单的演示,所以我们将创建一个用白色填充到一定高度的图像。该网络的目标是预测被白色覆盖的图像的比例。这可以很容易地用于从真实图像预测更复杂的属性,如其他教程所示。
例如:


在上图中,我们希望网络预测为0.47,因为47%的图像填充为白色。在底图中,我们希望网络预测0.76,因为76%的图像填充为白色。
在实际环境中,你可能会从文件中加载数据。在这里,我们将动态创建它:
def ReadRandomImage():
FillLevel=np.random.random() # Set random fill level
Img=np.zeros([900,900,3],np.uint8) # Create black image
Img[0:int(FillLevel*900),:]=255 # Fill the image
transformImg=tf.Compose([tf.ToPILImage(),
tf.Resize((height,width)),tf.ToTensor(),tf.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]) # Set image transformation
Img=transformImg(Img) # Transform to pytorch
return Img,FillLevel
在第一部分中,我们创建图像:
FillLevel=np.random.random() # Set random fill level
Img=np.zeros([900,900,3],np.uint8) # Create black image
Img[0:int(FillLevel*900),:]=255 # Fill the image
第一行选择0–1之间的随机数作为填充级别。
Img=np.zeros([900,900,3])创建一个大小为900X900的矩阵,填充零作为图像。这相当于一个高度和宽度为900的黑色图像。图像有3个对应于RGB的通道。
接下来,我们用白色填充图像的顶部,直到填充水平线。
Img[0:int(FillLevel*900),:]=255
现在我们创建了图像,我们对其进行处理并将其转换为Pytorch格式:
transformImg=tf.Compose([tf.ToPILImage(),
tf.Resize((height,width)),tf.ToTensor(),tf.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]) # Set image transformation
这定义了一组将应用于图像的变换。这包括转换为PIL格式(转换的标准格式),以及调整大小和转换为PyTorch格式。
对于图像,我们还通过减去平均值并除以像素强度来标准化图像中像素的强度。
对于我们的简单图像,标准化和大小调整并不是真正需要的,但这些转换对于真实图像很重要。
接下来,我们将变换应用于图像:
Img=transformImg(Img)
对于训练,我们需要使用一批图像。这意味着在4D矩阵中,多个图像相互叠加。我们使用以下函数创建batch:
def LoadBatch(): # Load batch of images images = torch.zeros([batchSize,3,height,width]) FillLevel = torch.zeros([batchSize]) for i in range(batchSize): images[i],FillLevel[i]=ReadRandomImage() return images,FillLevel
第一行创建一个空的4d矩阵,该矩阵将存储尺寸为[batchSize,Channel,height,width]的图像,其中Channel是图像的层数;这是RGB图像的3。下一行创建一个数组,其中存储填充级别。这将作为我们训练的标签。
下一部分使用前面定义的ReadRandomImage函数将图像集和填充级别加载到空矩阵:
for i in range(batchSize): images[i],FillLevel[i]=ReadRandomImage()
现在我们可以加载数据了,是时候加载神经网络了:
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
Net = torchvision.models.resnet18(pretrained=True) # Load net
Net.fc = torch.nn.Linear(in_features=512, out_features=1, bias=True)
Net = Net.to(device)
optimizer = torch.optim.Adam(params=Net.parameters(),lr=Learning_Rate)
第一部分是确定计算机是否有GPU或CPU。如果有Cuda GPU,训练将在GPU上进行:
device = torch.device(‘cuda’) if torch.cuda.is_available() else torch.device(‘cpu’)
对于任何实际数据集,使用CPU进行训练都非常缓慢。
接下来,我们加载用于图像分类的网络:
Net = torchvision.models.resnet18(pretrained=True)
torchvision.models包含许多有用的图像分类模型。Reseet18是一个轻量级的分类模型,适用于低资源训练或简单的数据集。对于更难的问题,最好使用resenet50(请注意,数字指的是网络中的层数)。
通过设置pretrained=True,我们在Imagenet数据集上加载带有预训练权重的网络。
在学习新问题时,最好从预训练的模型开始,因为它允许网络使用以前的经验并更快地收敛。
我们可以看到我们刚刚通过print(Net)查看网络的所有结构和所有层:
print(Net)
…
…
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
这会按使用顺序打印层。
网络的最后一层是线性变换,输入512层,输出1000层。1000代表输出类的数量(这个网络是在图像网络上训练的,图像网络将图像分为1000个类中的一个)。
因为我们只想预测一个值,所以我们想用一个输出的新线性层来代替它:
Net.fc = torch.nn.Linear(in_features=512, out_features=1, bias=True)
公平地说,这部分是可选的,因为一个有1000个输出通道的网络只需忽略999个通道就可以预测一个值。但这样更优雅。
接下来,我们将网络加载到GPU或CPU设备中:
Net=Net.to(device)
最后,我们加载一个优化器:
optimizer=torch.optim.Adam(params=Net.parameters(),lr=Learning_Rate) # Create adam optimizer
优化器将在反向传播步骤中控制梯度速率。Adam是最快的优化器之一。
最后,我们通过加载数据开始训练,使用网络进行预测:
AverageLoss=np.zeros([50]) # Save average loss for display
for itr in range(2001): # Training loop
images,GTFillLevel=LoadBatch() # Load taining batch
images=torch.autograd.Variable(images,requires_grad=False). to(device)
GTFillLevel = torch.autograd.Variable(GTFillLevel,
requires_grad=False).to(device)
PredLevel=Net(images) # make prediction
首先,我们希望保存训练期间的平均损失;我们创建一个数组来存储最后50步的损失。
AverageLoss=np.zeros([50])
这将使我们能够跟踪网络的学习情况。
我们将训练2000个步骤:
for itr in range(2000):
LoadBatch在前面定义,帮助加载一批图像及其填充级别。
torch.autograd.Variable:将数据转换成网络可以使用的梯度变量。我们设置Requires_grad=False,因为我们只将梯度应用于网络的层。to(device) 将张量复制到对应的设备(GPU/CPU)。
最后,我们将图像输入网络,得到预测结果。
PredLevel=Net(images)
一旦我们做出预测,我们可以将其与实际填充水平进行比较,并计算损失。损失是图像的预测和真实填充水平之间的绝对差(L1):
Loss=torch.abs(PredLevel-GTFillLevel).mean()
请注意,我们不是将损失应用于一张图像,而是应用于批次中的多张图像,因此我们需要将损失的平均值作为单个数字。
一旦我们计算了损失,我们就可以应用反向传播并改变权重。
Loss.backward() # Backpropogate loss
Optimizer.step() # Apply gradient descent change to wei
在训练期间,我们想看看我们的平均损失是否减少,看看网络是否真的学到了什么。
因此,我们将最后50个损失值存储在一个数组中,并显示每个步骤的平均值:
AverageLoss[itr%50]=Loss.data.cpu().numpy() # Save loss average
print(itr,") Loss=",Loss.data.cpu().numpy(),'AverageLoss',AverageLoss.mean())
这涵盖了整个训练阶段,但我们还需要保存经过训练的模型。否则,一旦程序停止,它就会丢失。
保存很费时,所以我们希望大约每200步只做一次:
if itr % 200 == 0: print(“Saving Model” +str(itr) + “.torch”)
torch.save(Net.state_dict(), str(itr) + “.torch”)
在运行这个脚本大约200步之后,网络应该会给出很好的结果。
总共40行代码,不包括空格。
训练并保存网络后,可以加载网络进行预测:
https://github.com/sagieppel/Train-neural-net-to-predict-continuous-property-from-an-image-in-40-lines-of-code-with-PyTorch/blob/main/Infer.py
该脚本加载你之前训练和保存的网络,并使用它进行预测。
这里的大部分代码与训练脚本相同,只有几处不同:
Net.load_state_dict(torch.load(modelPath)) # Load trained model
从modelPath中的文件加载我们之前训练和保存的网络
#Net.eval()
将网络从训练模式转换为评估模式。这主要意味着不会计算批次标准化统计数据。
虽然使用它通常是一个好主意,但在我们的例子中,它实际上会降低准确性,因此我们将在没有它的情况下使用网络。
with torch.no_grad():
这意味着网络运行时没有收集梯度。梯度只与训练相关,收集梯度需要大量资源。
感谢阅读!
原文标题:用Pytorch训练神经网络
郑重声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。
相关阅读




猜你喜欢
-
Pytorch图像检索实践
2022-04-08 -
国网新疆电力开发应用智能分类程序
2022-03-30 -
建立卷积神经网络模型
2022-03-02 -
神经网络改善了太阳能发电的预测
2021-10-25 -
基于模拟-优化方法的地下水污染源溯源辨识
2021-08-30 -
如何使用乳腺癌数据集的人工神经网络?
2021-06-30 -
有什么办法能在边缘设备上拟合大型神经网络?
2021-06-29 -
SCR脱硝系统多目标优化控制研究
2021-06-25 -
数据格式转化,PyTorch就是救星!
2021-06-10 -
如何在神经网络中初始化权重和偏差?
2021-06-07