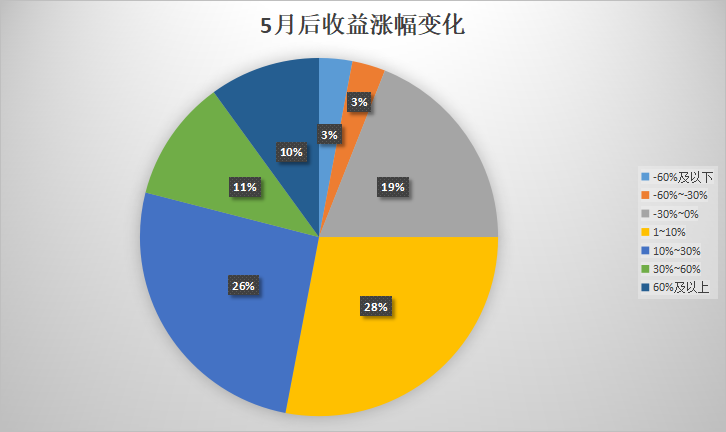
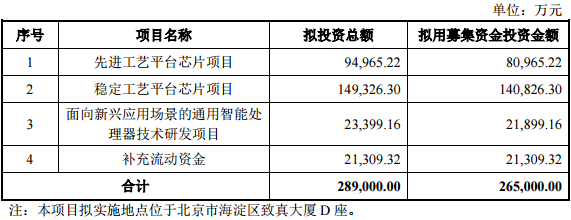
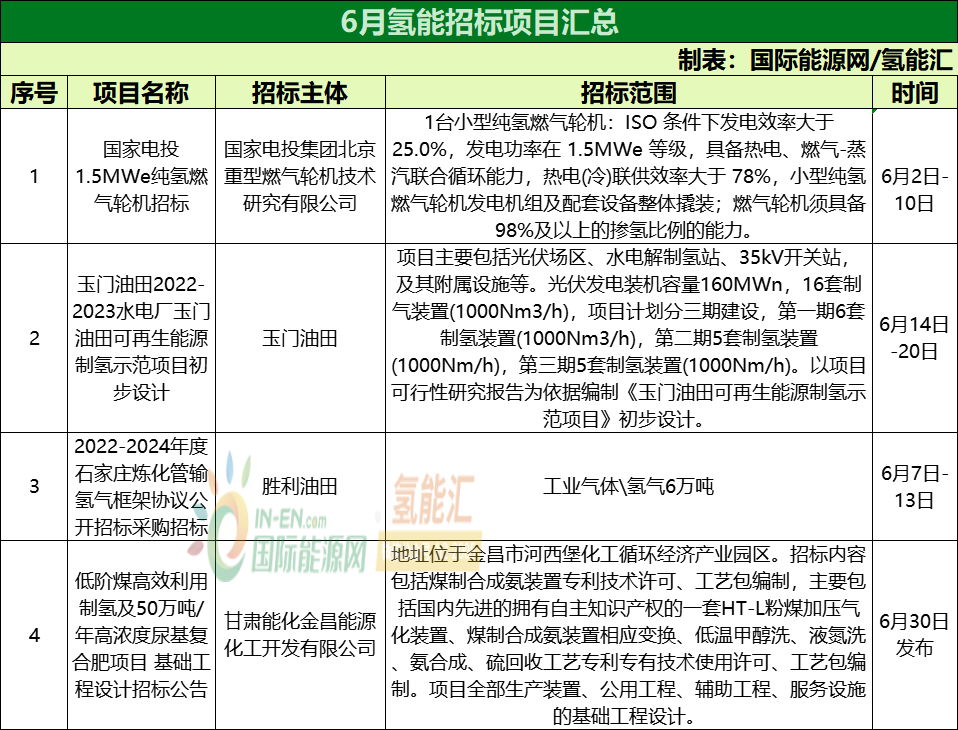
自动生成VGG图像注释文件
在计算机视觉领域,实例分割是当今最热门的话题之一。
它包括图像中对象的检测/分割,即特定对象的定位及其所属像素的关联。像任何一种机器学习系统一样,训练主干结构需要大量图像。更具体地说,需要大量注释来训练神经网络的定位功能。
注释是一项耗时的活动,可以决定项目是否会成功。因此,必须谨慎处理,以提高生产率。
在卫星图像领域,可以利用免费数据集来利用研究人员或注释人员以前所做的工作。这些数据集通常是由研究人员在从开源图像构建数据集、进行前后处理并用于训练和测试自己的人工智能研究系统后发布的。
语义分割和实例分割有点不同,但在建筑物的情况下,一个可以帮助另一个。
事实上,建筑物通常是独特的,可以在任何图像上进行分离。利用这种考虑,可以从二值标签图像中为每个建筑生成单独的遮罩,然后用于更快地训练实例分割算法,如Mask RCNN。注释不必手动执行,这是该技术的主要优点。下面是一些如何做的提示!
JSON文件格式
Mask RCNN Matterport实现以及FAIR Detectron2平台使用JSON文件为训练图像数据集加载注释。这种文件格式用于许多计算机科学应用,因为它允许以成对属性值的格式轻松存储和共享字母数字信息。
它是为JavaScript语言构建的,但如今,它被用于许多其他编程语言,如Python。专门的库已经建立起来,能够在Python代码中以文本文件的形式生成和解析JSON格式的数据。VGG注释工具格式中Mask RCNN使用的典型JSON文件将具有以下形状:
{
"image1.png9259408": {
"filename": "image1.png",
"size": 9259408,
"regions": [
{
"shape_attributes": {
"name": "polygon",
"all_points_x": [
314,
55,
71,
303,
318,
538,
],
"all_points_y": [
1097,
1093,
1450,
1450,
1505,
1474,
]
},
"region_attributes": {
"class": "building"
}
},
{
"shape_attributes": {
"name": "rect",
"x": 515,
"y": 1808,
"width": 578,
"height": 185
},
"region_attributes": {
"class": "apple"
}
}
],
"file_attributes": {}
},
"0030fd0e6378.png236322": {
"filename": "0030fd0e6378.png",
"size": 236322,
"regions": [
{
"shape_attributes": {
"name": "polygon",
"all_points_x": [
122,
294,
258,
67,
32
],
"all_points_y": [
92,
113,
231,
221,
132
]
},
"region_attributes": {
"class": "apple"
}
},
{
"shape_attributes": {
"name": "circle",
"cx": 210,
"cy": 303,
"r": 47
},
"region_attributes": {
"class": "swan"
}
}
],
"file_attributes": {}
}
}
一个JSON注释文件收集所有注释数据。每个图像注释都堆积在一个大的JSON文件中。
一个图像由其标识符标识。该标识符由四个属性描述:图像的名称(文件名)、其在磁盘上的大小(大小)、注释的形状(区域)和图像上的一些元数据(文件属性)。
每个注释都可以由两个元素来描述:形状描述(形状属性)和注释数据(区域属性)。形状属性描述由注释的形状(名称)和两个整数的有序列表(所有点x和所有点y)组成,它们表示构成遮罩注释的点的x和y坐标。注释数据region_attributes可以调整,注释类可以保存以用于多类分割。
第四个标识符属性名为file_attributes,可用于存储注释图像上的任何信息。
在语法方面,让我们注意到大括号{}通常用于分隔相同类型的元素,以及引用描述一个元素的属性。方括号[]用于表示参数列表。
幸运的是,Python有一个库供我们读写JSON文件。使用带有通用语法的import json代码片段可以轻松加载它,以读取和写入文本文件。
在下一章中,我们将讨论如何将二进制标签图像转换为VGG注释,尤其是如何使用JSON语法编写注释文件。
生成注释JSON文件
本文提出的主要思想是将二进制标签图像转换为VGG注释格式的掩码JSON文件。对二值标签图像的每个形状进行个性化处理,以将其转化为遮罩元素,例如分割。
转换主要使用著名的OpenCV图形库执行,该库在Python中易于使用。
def Annot(preprocess_path, res=0.6, surf=100, eps=0.01):
"""
preprocess_path : path to folder with gt and images subfolder containing ground truth binary label image and visual imagery
res : spatial resolution of images in meter
surf : the minimum surface of roof considered in the study in square meter
eps : the index for Ramer–Douglas–Peucker (RDP) algorithm for contours approx to decrease nb of points describing a contours
"""
jsonf = {} # only one big annotation file
with open(os.path.join(preprocess_path,'via_region_data.json'), 'w') as js_file:
gt_path = os.path.join(preprocess_path, 'gt')
images_path = os.path.join(preprocess_path, 'images')
# All the elements in the images folders
lst = os.listdir(images_path)
for elt in tqdm(lst, desc='lst'):
# Read the binary mask, and find the contours associated
gray = cv2.imread(os.path.join(gt_path, elt))
imgray = cv2.cvtColor(gray, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(imgray, 127, 255, 0)
contours, _ = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# https://www.pyimagesearch.com/2021/10/06/opencv-contour-approximation/
# Contours approximation based on Ramer–Douglas–Peucker (RDP) algorithm
areas = [cv2.contourArea(contours[idx])*res*res for idx in range(len(contours))]
large_contour = []
for i in range(len(areas)):
if areas[i]>surf:
large_contour.append(contours[i])
approx_contour = [cv2.approxPolyDP(c, eps * cv2.arcLength(c, True), True) for c in large_contour]
# -------------------------------------------------------------------------------
# BUILDING VGG ANNTOTATION TOOL ANNOTATIONS LIKE
if len(approx_contour) > 0:
regions = [0 for i in range(len(approx_contour))]
for i in range(len(approx_contour)):
shape_attributes = {}
region_attributes = {}
region_attributes['class'] = 'roof'
regionsi = {}
shape_attributes['name'] = 'polygon'
shape_attributes['all_points_x'] = approx_contour[i][:, 0][:, 0].tolist()
# https://stackoverflow.com/questions/26646362/numpy-array-is-not-json-serializable
shape_attributes['all_points_y'] = approx_contour[i][:, 0][:, 1].tolist()
regionsi['shape_attributes'] = shape_attributes
regionsi['region_attributes'] = region_attributes
regions[i] = regionsi
size = os.path.getsize(os.path.join(images_path, elt))
name = elt + str(size)
json_elt = {}
json_elt['filename'] = elt
json_elt['size'] = str(size)
json_elt['regions'] = regions
json_elt['file_attributes'] = {}
jsonf[name] = json_elt
json.dump(jsonf, js_file)
第一行是为真实标签和图像文件夹构建正确的文件夹路径,并创建JSON文件注释。
首先,使用cv2.findContours将二进制遮罩切割成轮廓。大多数转换(阈值、灰度转换)实际上并不需要,因为数据已经是二值图像。cv2.findContours函数提供一个等高线列表,作为一个点列表,这些点的坐标在图像的参考系中表示。
在大型建筑屋顶项目中,可以使用自定义OpenCV函数来导出屋顶表面,然后将其转换为平方米,并仅选择具有足够面积的屋顶。在这种情况下,可以使用Ramer–Douglas–Peucker(RDP)算法来简化和近似检测到的轮廓,以便更紧凑地存储注释数据。此时,你应该有一个点列表,这些点代表在二值图像上检测到的轮廓。
现在,你需要将整个轮廓点列表转换为一个大的用于掩码RCNN算法的via_region_data.json文件。对于JSON注释,数据需要具有第一段中指定的格式。字典主要在将数据推送到JSON文件之前使用。
根据轮廓[]的数量,需要特定数量的 [:,0]才能获取正确的数据。描述轮廓的整数数组必须转换为JSON可序列化数据。制作VGG注释JSON文件与制作俄罗斯玩偶非常相似。你可以创建一个空字典,指定其一个(或多个)属性的值,然后将其作为更高级别属性的值传递,以将其封装到更大的字典中。我们注意到,对于多类分割或对象检测,region_attributes可以包含一个属性类,该属性类的掩码在shape_attributes参数中指定。
最后,在将所有图像数据放入JSON文件之前,每个图像数据都存储在一个大的“json”元素中,其名称+大小字符串作为标识符。这一点非常重要,因为如果每次运行新图像时都写入JSON文件,JSON文件的掩码RCNN导入将失败。这是因为json.load只读取第一组大括号{}的内容,无法解释下一组大括号。
就这样!让我们看看这个过程的结果是什么!
检查注释显示
这一小章将展示上述过程的图形化使用。使用的主要是美国地质调查局通过国家地图服务公开发布的美国城市图像(芝加哥、奥斯汀、旧金山)。
美国地质调查局国家地理空间计划提供的地图服务和数据。该服务是开源的,所以你可以对数据做任何你想做的事情!
在这篇文章中,处理了德克萨斯州奥斯汀附近的高分辨率图像(空间分辨率=0.3米/像素)。
第一个图像是视觉彩色图像,通常以GeoTiff格式提供,它也包含嵌入的地理空间数据。它以美国城市环境的城市场景为特色。渲染由三个光谱视觉图像构建:通常的蓝色、绿色和红色。但在更复杂的图像中,图像供应商可以提供近红外图像,以便能够生成CNIR(彩色+近红外图像),以分析光谱图像的不同方面。

第二个图像显示二进制标签图像。可以看出,标签包含了与建筑物相关的每一个像素,即使是最小的弯曲形状的像素。每个建筑都可以单独识别,因为建筑不能重叠,这就证明了整个过程的合理性。

第三幅图像由二值标签1和cv2检测到的轮廓组成,以红色突出显示。显示的等高线是来自OpenCV函数的原始数据,没有被过滤掉,因此即使是最小的建筑也会被显示出来。需要注意的是,cv2.findContours是一种像素级的转换:由一个像素连接的两座建筑将被分割在一起,而只有一行暗像素就足以将两座相邻的建筑分别分割。

第四幅图像显示具有过滤后的近似轮廓的二值标签图像。正如第二章所说,就屋顶项目而言,对面积小于100平方米的建筑不感兴趣。它还将执行轮廓近似以减小注释文件的大小。因此,仅在大型建筑周围绘制轮廓,在某些情况下,轮廓与建筑形状不完全匹配,无法启发轮廓近似。

第五张也是最后一张图像显示了通常的实例分割可视化,可以使用inspect_roof_data等工具绘制。大型建筑的屋顶被单独分割。

结论
本文展示的过程展示了如何将语义数据集转换为实例分割训练数据集。然后可以使用它来有效地训练Mask-RCNN算法。该过程也可以重复使用和修改,以适应具有不同输入标签形状的数据集。
原文标题:自动生成VGG图像注释文件
郑重声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。
相关阅读





猜你喜欢
-
使用 Fast ai 进行图像分类
2022-04-26 -
Pytorch图像检索实践
2022-04-08 -
有毒废物使太阳能的吱吱作响的清洁图像
2022-04-04 -
使用CV2和Keras OCR从图像中删除文本
2022-03-28 -
利用生成对抗网络生成海洋塑料合成图像
2022-03-17 -
使用球员图像姿势的板球击球分类
2022-03-15 -
使用简单方法在图像中检测血细胞
2022-03-14 -
CCD图像传感器和CMOS图像传感器的区别详解
2022-03-11 -
?使用Mediapipe对图像进行手部地标检测
2022-03-08 -
在OpenCV中使用图像像素
2022-03-03 -
使用OpenCV在Python中进行图像操作
2022-02-14 -
使用迁移学习加强你的图像搜索
2022-02-10 -
基于域相关的图像增强
2022-01-06 -
探索如何通过向AI提供大量药丸图像来训练AI检测定制药丸
2021-12-15 -
人工智能技术自动生成数据标签方面所做的工作
2021-12-06