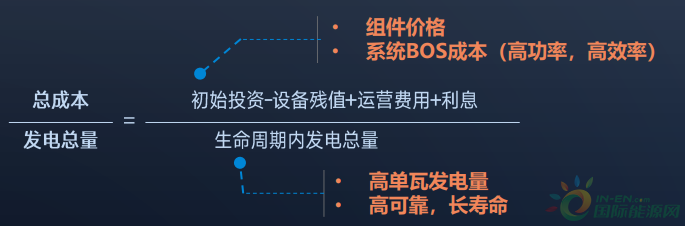
SageMaker TensorFlow对象检测模型
这篇文章描述了如何在Amazon SageMaker中使用TensorFlow对象检测模型API来实现这一点。
首先,基于AWS示例笔记本,将解释如何使用SageMaker端点在单个图像上运行模型。对于较小的图像,这种方法可行,但对于较大的图像,我们会遇到问题。
为了解决这些问题,改用批处理转换作业。

起点:使用SageMaker TensorFLow对象检测API进行模型推断
AWS提供了一些关于GitHub如何使用SageMaker的好例子。
使用此示例使用TensorFlow对象检测API对对象检测模型进行预测:

将模型部署为端点时,可以通过调用端点,使用该模型一次推断一个图像。此代码取自示例笔记本,显示了如何定义TensorFlowModel并将其部署为模型端点:
import cv2
import sagemaker
from sagemaker.utils import name_from_base
from sagemaker.tensorflow import TensorFlowModel
role = sagemaker.get_execution_role()
model_artefact = '<your-model-s3-path>'
model_endpoint = TensorFlowModel(
name=name_from_base('tf2-object-detection'),
model_data=model_artefact,
role=role,
framework_version='2.2',
)
predictor = model_endpoint.deploy(initial_instance_count=1, instance_type='ml.m5.large')
然后,将图像加载为NumPy数组,并将其解析为列表,以便将其传递给端点:
def image_file_to_tensor(path):
cv_img = cv2.imread(path,1).astype('uint8')
cv_img = cv2.cvtColor(cv_img, cv2.COLOR_BGR2RGB)
return cv_img
img = image_file_to_tensor('test_images/22673445.jpg')
input = {
'instances': [img.tolist()]
}
最后,调用端点:
detections = predictor.predict(input)['predictions'][0]
问题:端点请求负载大小太大
这在使用小图像时很好,因为API调用的请求负载足够小。然而,当使用较大的图片时,API返回413错误。这意味着有效负载超过了允许的大小,即6 MB。
当然,我们可以在调用端点之前调整图像的大小,但我想使用批处理转换作业。
解决方案:改用批处理转换作业
使用SageMaker批量转换作业,你可以定义自己的最大负载大小,这样我们就不会遇到413个错误。其次,这些作业可用于一次性处理全套图像。
图像需要存储在S3存储桶中。所有图像都以批处理模式(名称中的内容)进行处理,预测也存储在S3上。
为了使用批处理转换作业,我们再次定义了TensorFlowModel,但这次我们还定义了入口点和源目录:
model_batch = TensorFlowModel(
name=name_from_base('tf2-object-detection'),
model_data=model_artifact,
role=role,
framework_version='2.2',
entry_point='inference.py',
source_dir='.',
)
inference.py代码转换模型的输入和输出数据,如文档中所述。此代码需要将请求负载(图像)更改为NumPy数组,并将其解析为列表对象。
从这个示例开始,我更改了代码,使其加载图像并将其转换为NumPy数组。inference.py中input_handler函数更改为以下内容:
import io
import json
import numpy as np
from PIL import Image
def input_handler(data, context):
""" Pre-process request input before it is sent to TensorFlow Serving REST API
Args:
data (obj): the request data, in format of dict or string
context (Context): an object containing request and configuration details
Returns:
(dict): a JSON-serializable dict that contains request body and headers
"""
if context.request_content_type == "application/x-image":
payload = data.read() image = Image.open(io.BytesIO(payload)) array = np.asarray(image) return json.dumps({'instances': [array.tolist()]}) raise ValueError('{{"error": "unsupported content type {}"}}'.format( context.request_content_type or "unknown"))
注意,在上面的代码中排除了output_handler函数。
此函数需要Python包NumPy和Pillow,它们未安装在运行批处理推断作业的机器上。
我们可以创建自己的镜像并使用该镜像(在TensorFlowModel对象初始化时使用image_uri关键字)。
也可以提供requirements.txt并将其存储在笔记本所在的文件夹中(称为source_dir=“.”)。该文件在镜像引导期间用于使用pip安装所需的包。内容为:
numpy
pillow
首先,想使用OpenCV(就像在endpoint示例中一样),但该软件包不太容易安装。
我们现在使用模型创建transformer对象,而不是将模型部署为模型端点:
input_path = "s3://bucket/input"
output_path = "s3://bucket/output"
tensorflow_serving_transformer = model_batch.transformer(
instance_count=1,
instance_type="ml.m5.large",
max_concurrent_transforms=1,
max_payload=5,
output_path=output_path,
)
最后,使用transform:
tensorflow_serving_transformer.transform(
input_path,
content_type="application/x-image",
)
图像由模型处理,结果将作为JSON文件最终在output_path bucket中。命名等于输入文件名,后跟.out扩展名。你还可以调整和优化实例类型、最大负载等。
最后
这很可能不是最具成本效益的方法,因为我们将图像作为NumPy数组传递给转换器。
此外,我们还可以在inference.py中调整output_handler函数压缩并存储在S3上的JSON,或仅返回相关检测。
原文标题:SageMaker TensorFlow对象检测模型
郑重声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。
相关阅读


猜你喜欢
-
Lua面向对象编程的基本原理示例
2022-08-16 -
晶盛机电向特定对象发行A股,共募集资金14.19亿元
2022-08-02 -
药物发现中的斑马鱼疾病模型
2022-07-28 -
Meta免费开源AI模型NLLB-200!可精准翻译超过200种语言
2022-07-08 -
中国电科院研发变电模型转换工具实现自动化系统模型向信息化系统模型的自动转换
2022-07-06 -
世界一流财务 | 全面预算管理帮助集团企业构建7大核心能力
2022-06-28 -
从科研创新到产业落地 华为发布人工智能大模型全流程使能体系
2022-06-15 -
大全能源110亿定增获批!
2022-06-10 -
自然语言处理序列模型——HMM隐马尔可夫模型
2022-04-13 -
4种在生产中扰乱计算机视觉模型的方法
2022-04-06 -
国网新疆电力开发应用智能分类程序
2022-03-30 -
又一款15MW漂浮式海上风电基础上线在即!
2022-03-30 -
西北电网调控云新能源模型管理平台正式上线运行
2022-03-21 -
FORESEE参数模型提取设计仿真
2022-03-15 -
精彩论文 | 火电机组一次调频功率响应特性精细化建模
2022-03-09