使用Pytesseract进行光学字符识别
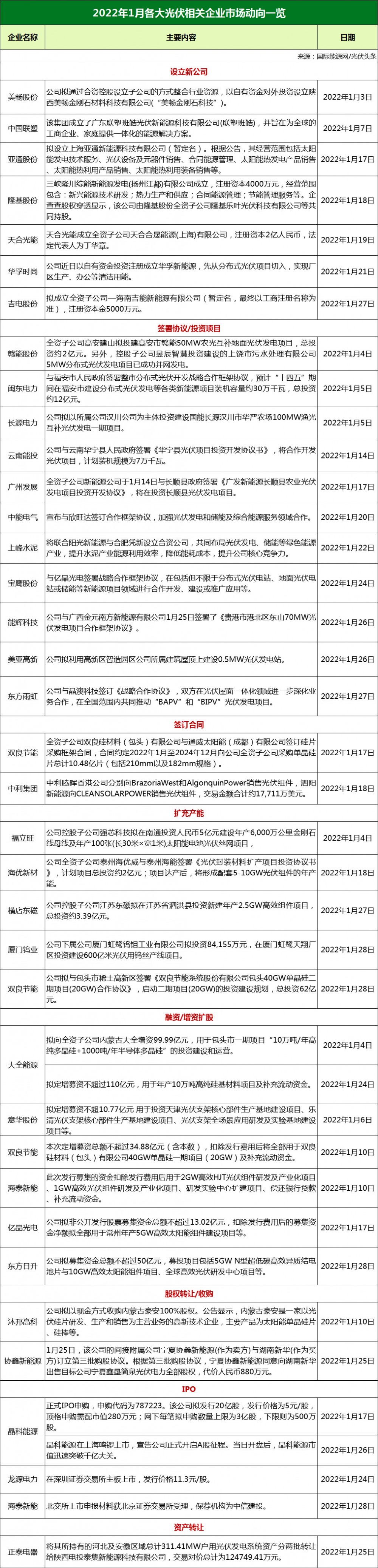
概述
本文,我们将使用计算机视觉技术从图像中提取文本。提取文本后,我们将在该文本上应用 OpenCV 的一些基本功能来增强它并获得更准确的结果。这个项目将非常有用,因为它可以节省从图像打字的时间和精力。
范围
· 对于将从图像中获取文本的大型组织而言,此应用程序可能会节省时间。
· 它可以打开“无纸化文档”的世界,这也有助于升级存储。
· 它还可以帮助自动化过程,因为它可以从图像本身中获取文本。
我们将导入requests库以获取 git 文件和图像的 URL 。
#import requests to install tesseract
import requests
注意:现在要下载 tesseract 文件,只需转到我将在函数中作为参数提供的链接,但我只是提供另一种下载 tesseract 文件的方法。
# Downloading tesseract-ocr file
r = requests.get("https://raw.githubusercontent.com/tesseract-ocr/tessdata/4.00/ind.traineddata", stream = True)将数据写入文件以避免路径问题
with open("ind.traineddata", "wb") as file:
for block in r.iter_content(chunk_size = 1024):
if block:
file.write(block)
我们现在将下载Pytesseract 库运行所需的tesseract,并将文件保存在open() 函数的路径中。
!pip install pytesseract
如果你想将其安装在笔记本中,此命令将安装 Pytesseract 模块
Requirement already satisfied: pytesseract in c:programdataanaconda3libsite-packages (0.3.8)
Requirement already satisfied: Pillow in c:programdataanaconda3libsite-packages (from pytesseract) (8.0.1)
在这一步中,我们将安装 OCR 所需的库,我们还将导入 IPython 函数以清除不需要的函数。
安装光学字符识别所需的库
! apt install tesseract-ocr libtesseract-dev libmagickwand-dev
导入 IPython 以清除不重要的输出
from IPython.display import HTML, clear_output
clear_output()
现在,我们将安装Pytesseract 和 OpenCV库,它们是我们文本识别的灵魂
安装Pytesseract 和 OpenCV!
pip install pytesseract wand opencv-python
clear_output()
导入所需的库
# Import libraries
from PIL import Image
import pytesseract
import cv2
import numpy as np
from pytesseract import Output
import re
在这一步中,我们将打开一个图像调整其大小,然后再次保存以供进一步使用和可视化。
从URL读取图像
image = Image.open(requests.get('https://i.stack.imgur.com/pbIdS.png', stream=True).raw)
image = image.resize((300,150))
image.save('sample.png')
image
输出:

设置tesseract的路径
pytesseract.pytesseract.tesseract_cmd = r'C:Program FilesTesseract-OCRtesseract.exe'
注意:上面的命令将在系统配置中设置tesseract库的路径,如果路径没有根据系统配置设置,那么即使安装了tesseract也会抛出错误。
在这里,我们将使用自定义配置从图像中提取文本。
# Simply extracting text from image
custom_config = r'-l eng --oem 3 --psm 6'
text = pytesseract.image_to_string(image,config=custom_config)
print(text)
输出:

在自定义配置中,你可以看到**“eng”表示英语,即它会识别英文字母,你还可以添加多种语言,“PSM”表示页面分割**,它设置了块如何识别字符,“OEM”是默认配置。
现在,我们将通过用空字符串替换符号,从提取的文本中删除不需要的符号
# Extracting text from image and removing irrelevant symbols from characters
try:
text=pytesseract.image_to_string(image,lang="eng")
characters_to_remove = "!()@—*“>+-/,'|?#%$&^_~"
new_string = text
for character in characters_to_remove:
new_string = new_string.replace(character, "")
print(new_string)
except IOError as e:
输出:

在下面的单元格中,我们将图像读入OpenCV格式以进一步处理。当我们需要从复杂图像中提取文本时,这是必需的。
现在我们将执行OpenCV操作以从复杂图像中获取文本。
image = cv2.imread('sample.png') # will read in the array format
输出:

将图像转换为灰度图像,使其处理起来不那么复杂,因为它只有 0 和 1 两个值。这里我们使用cv2.cvtColor()方法将彩色图像转换为灰度格式,而cv2.cvtColor 实际上可以帮助图像的 150 色转换。
灰度图像
def get_grayscale(image):
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = get_grayscale(image)
Image.fromarray(gray)
输出:
现在我们将模糊图像,以便我们可以从图像中去除噪声。在这里,我们使用函数cv2.medianBlur() 函数以减少图像中的噪声**,**模糊基本上是通过应用相关平滑滤波器来平滑图像的技术,是图像处理中广泛使用的方法之一。
降噪
def remove_noise(image):
return cv2.medianBlur(image,5)
noise = remove_noise(gray)
Image.fromarray(gray)
输出:
我们将在这里进行阈值变换。阈值适用于简单的概念,即当像素值低于给定的阈值时,颜色为白色,否则像素颜色正好相反,即黑色。使用的函数是cv2.threshold。
阈值
def thresholding(image):
# source image, grayscale image
return cv2.threshold(image, 0, 255, cv2.THRESH_BINARY +
cv2.THRESH_OTSU)[1]
thresh = thresholding(gray)
Image.fromarray(thresh)
输出:

这里我们正在做腐蚀变换。腐蚀变换是图像变换中最基本、最重要的步骤之一。腐蚀变换通常会拟合图像中缺失的形状和格子,这有助于在图像中稍微模糊或扭曲时识别字符。在这里,我们使用cv2 库中的erode()函数进行腐蚀转换。
腐蚀
def erode(image):
kernel = np.ones((5,5),np.uint8)
return cv2.erode(image, kernel, iterations = 1)
erode = erode(gray)
Image.fromarray(erode)
输出:

在这里,我们将执行形态变换。形态变换是最适合二值图像的技术之一,它根据图像的像素值对图像进行排序,而不是在考虑阈值的情况下对图像的数值进行排序。
形态变换
def opening(image):
kernel = np.ones((5,5),np.uint8)
return cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel)
opening = opening(gray)
Image.fromarray(opening)
输出:

在这里,我们试图匹配图像。当我们传递相同的图像进行匹配时,我们得到了99.99%的相似度。这里,模板匹配是一种在较大的图像中搜索和查找模板图像的位置的方法。对于模板匹配,我们使用cv2 库中的 match template()函数。
模板匹配
def match_template(image, template):
return cv2.matchTemplate(image, template, cv2.TM_CCOEFF_NORMED)
match = match_template(gray, gray)
match
输出:
array([[1.]], dtype=float32)
现在我们将通过在文本周围创建一个矩形来分隔文本中的每个字符。
# Drawing rectangle around text
img = cv2.imread('sample.png')
h, w, c = img.shape
boxes = pytesseract.image_to_boxes(img)
for b in boxes.splitlines():
b = b.split(' ')
img = cv2.rectangle(img, (int(b[1]), h - int(b[2])), (int(b[3]), h - int(b[4])), (0, 255, 0), 2)
Image.fromarray(img)
输出:

最后,我们可以围绕特定的图案或单词绘制矩形。
# Drawing pattern on specific pattern or word
img = cv2.imread('sample.png')
d = pytesseract.image_to_data(img, output_type=Output.DICT)
keys = list(d.keys())
date_pattern = 'artificially'
n_boxes = len(d['text'])
for i in range(n_boxes):
if float(d['conf'][i]) > 60:
if re.match(date_pattern, d['text'][i]):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
Image.fromarray(img)
输出:

结论
我们从学习如何安装用于文本提取的 tesseract 开始。接下来,我们拍摄了一张图像并从该图像中提取了文本。我们了解到我们需要使用 OpenCV 的某些图像转换函数来从复杂图像中提取文本。
尾注
希望你们会喜欢这个使用 Pytesseract逐步学习光学字符识别的方法。
原文标题:使用Pytesseract进行光学字符识别
郑重声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。
相关阅读





猜你喜欢
-
python的数字与字符串相互转换
2022-01-24 -
具有集成光学元件的太阳能膜可提高光伏面板的性能
2021-12-17 -
选择代表性的字符串来测量功率损耗
2021-12-04 -
近4亿元,光学相干断层扫描成像技术公司获投资
2021-11-02 -
对话舜宇智能光学:让机器人像人一样看世界
2021-09-18 -
超快非线性光学技术之十六 利用多通腔压缩产生高功率少周期脉冲
2021-09-14 -
福特科光学回复科创板首轮问询
2021-09-10 -
光学测厚仪有什么类型?
2021-08-19 -
新光光电半年报净利增长378.99%,光学目标与场景仿真取得新进展
2021-08-10 -
一种新型光学系统,可用于100太瓦激光器研究
2021-08-03 -
苹果供应商伯恩光学递表拟上市
2021-08-03 -
日本科学家开发了基于PV的无线光学神经刺激器
2021-08-02 -
纺织服装行业纽扣的表面缺陷检测 全自动外观光学检测
2021-07-21 -
精密光学元组件及镜头公司福特科,科创板IPO获上交所问询
2021-07-20 -
当…几个模块字符串失败时,会发生什么?
2021-07-07